تثبيت Node.js في أبونتو لينكس
-
أحمد بكداش
- 9:10 م, الثلاثاء, 5 أبريل 2022
- 2105

في هذا المقال سنشرح تثبيت Node.js في أبونتو لينكس Ubuntu 21.10.
هي بيئة تشغيل مفتوحة المصدر لتطوير تطبيقات الخادم والشبكات.تسمح للمبرمجين بكتابة برمجيات بلغة جافاسكربت تعمل خارج مُتصفح الويب، ويقوم NodeJS بترجمتها إلى لغة تفهمها الآلة من خلال مُحرك جافاسكربت V8 المصمم من طرف جوجل، والمستخدم في متصفح كروم وتستخدمه باقي المتصفحات المبنية على نواة كروميوم، هذا يمكن المبرمجين من برمجة العديد من الأمور باستخدام لغة جافاسكربت وجعلها تعمل خارج المتصفح، كبرمجة الواجهة الخلفية للمواقع (back-end)، برمجة سكربت يعمل على سطر الآوامر، وكذلك برمجة تطبيقات بواجهات رُسومية باستخدام تقنيات مثل آلكترون (Electron).
تتم كتابة تطبيقات Node.js بلغة JavaScript، ويمكن تنفيذها خلال وقت تشغيل Node.js على أنظمة التشغيل OS X و Microsoft Windows و Linux.
يستخدم إطار Node.js لبرمجة تطبيقات الويب بالتحديد و صفحات الانترنت بشكل عام، يعتمد في عمله على ال .events
Node.js = بيئة وقت التشغيل + مكتبة جافا سكريبت.
سنسرد ثلاث طرق لتنصيب Node.js في أبونتو لينكس.
يمكن تثبيت Node.js في ابونتو لينكس مع NPM من مستودع أبونتو الأساسي Ubuntu Repository .
بداية سنقوم بتحديث أبونتو ,ومن ثم تثبيت الحزمة كما في السطور التالية::
$ sudo apt update
$ sudo apt install nodejs npm -yالإصدار الأخير من Node.js اثناء كتابة المقال هو v10.19.0 للتحقق انه تم تنصيبه تماما اختبر عبر الأمر التالي :
$ nodejs -v NVM هو اختصار ل Node Version Manager, هو حزمة سكريبت (shell script) يمكن المستخدم من التنقل بين أصدارات Node المختلفة تنصيبها أو حذفها ..الخ .
بداية نحتاج إلى تحميل سكريبت NVM عبر السطر التالي من محرر الأوامر:
$ curl https://raw.githubusercontent.com/creationix/nvm/master/install.sh | bash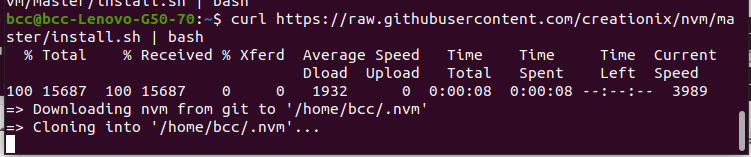
عندما ينتهي من التنصيب سيطلب منك أغلاق محرر الأوامر وإعادة تشغيله من جديد لتتمكن من المباشرة باستخدام الأوامر الخاصة ب nvm .
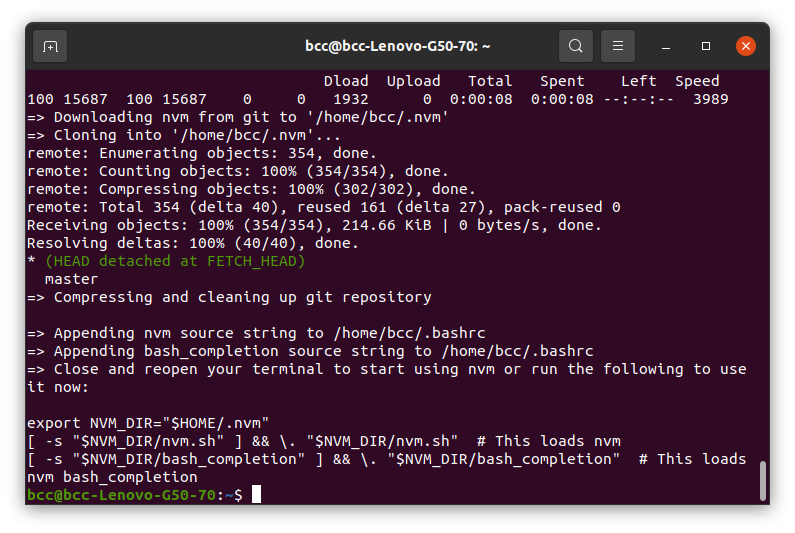
لنختبر إصدار NVM عبر الأمر التالي :
$ nvm --version
الآن لمعرفة الإصدارات المتاحة من Node.js التي يتوفر تنصيبها عبر NVM نستخدم الأمر التالي:
$ nvm list-remote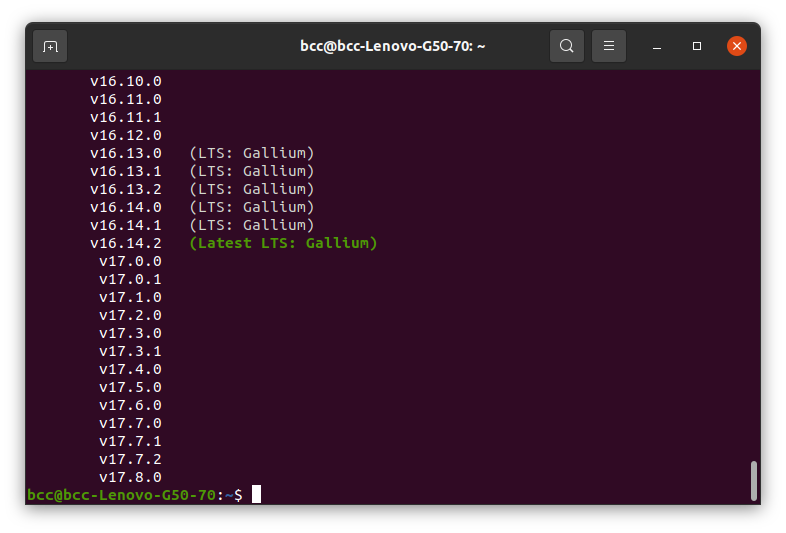
سيظهر على الشاشة قائمة بالإصدارات المتوفرة للتنصيب , بعضها ملحق بـ LTS , هذا الرمز يشير أن الإصدار يمتلك فترة دعم فني طويله (Long Time Support) تشمل التحديثات الأمنية والترقيعات الخ ..
لتنصيب إصدار LTS الأخير من Node.js على سبيل المثال , سنكتب الأمر التالي:
$ nvm install --lts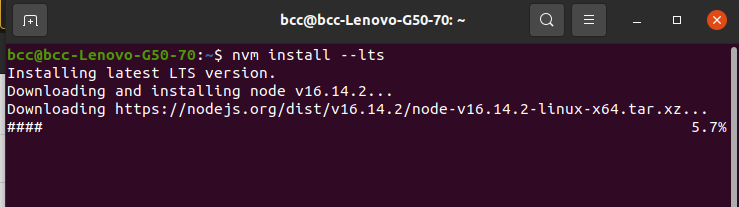
يمكننا التأكد من إصدار Node الذي تم تنصيبه عبر التالي:
$ node --versionإذا أردت العمل على إصدار 17.8.0 مثلا نستخدم الأمر التالي:
$ nvm install 17.8.0يمكن تنصيب اكثر من اصدار عبر NVM , يمكن معرفة ألإصدارت التي تم تنصيبها على النظام عبر التعلمية التالية :
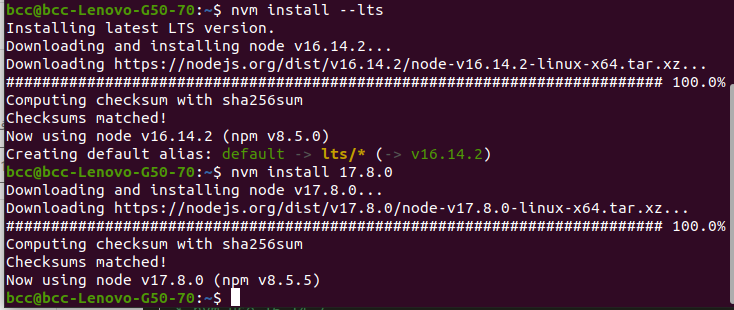
$ nvm ls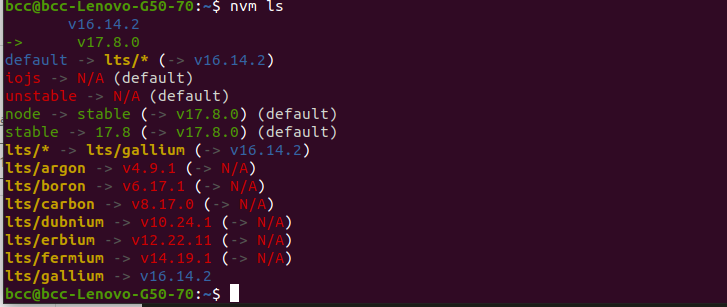
للتحول من إصدار إلى آخر عبر NVM سنستخدم الأمر nvm use على سبيل المثال للتحول للإصدار 16.14.2 كما يلي:
$ nvm use 16.14.2لجعل إصدار محدد هو الافتراضي نستخدم الأمر التالي:
$ nvm alias 16.14.2الأوامر التالية تسمح بتنصيب Node.js من مستودع Nodesource
$ curl -sL https://deb.nodesource.com/setup_14.x | sudo -E bash -
$ sudo apt install nodejs -y
$ npm --version
$ node --versionالطرق الثلاث تسمح بتنصيب node.js في أبونتو لينكس بسهوله , لكن الطريقة الأولى – مستودع أبونتو – قد لا تمنحك الحصول على الإصدار الأحدث من Node.js ,بينما يمكنك عبر NVM و Nodesource استخدام الإصدار الأحدث في عملك , تتيح لك NVM تحديدا التنقل بسهوله بين الإصدارات . لذا تبدو من وجهة نظري الخيار المفضل .

هل أعجبك المحتوى وتريد المزيد منه يصل إلى صندوق بريدك الإلكتروني بشكلٍ دوري؟
انضم إلى قائمة من يقدّرون محتوى إكسڤار واشترك بنشرتنا البريدية.

